Continuous Learning Strategies
While the community has not agreed yet on a shared categorization for CL strategies, here we propose a
three-label fuzzy categorization based on
[7] and
[10]:
- Architectural Strategies: specific architectures, layers, activation functions, and/or weight-freezing strategies are used to mitigate forgetting. Includes Dual-memories-models attempting to imitate Hippocampus – Cortex duality.
- Regularization Strategies: the loss function is extended with terms promoting selective consolidation of the weights which are important to retain past memories. Include regularization techniques such as weight sparsification, dropout, early stopping.
- Rehearsal Strategies: past information is periodically replayed to the model, to strengthen connections for memories it has already learned. A simple approach is storing part of the previous training data and interleaving them with new patterns for future training. A more challenging approach is pseudo-rehearsal with generative models.
In the last few years, a large number of CL strategies has been proposed. A
non-comprehensive,
cherry-picked list of the most popular strategies can be found below:
- CopyWeights with Re-init (CWR) [1]
- Progressing Neural Networks (PNN) [8]
- Elastic Weights Consolidation (EWC) [5]
- Synaptic Intelligence (SynInt) [7]
- Learning without Forgetting (LwF) [3]
- Incremental Classifier and Representation Learning (iCaRL) [6]
- Gradient Episodic Memory (GEM) [4]
In
Fig. 1 the
Venn diagram of the fuzzy classification of the aforementioned strategies is proposed. It is interesting to note the large space for yet-to-be-explored techniques merging the ideas of the three different categories.
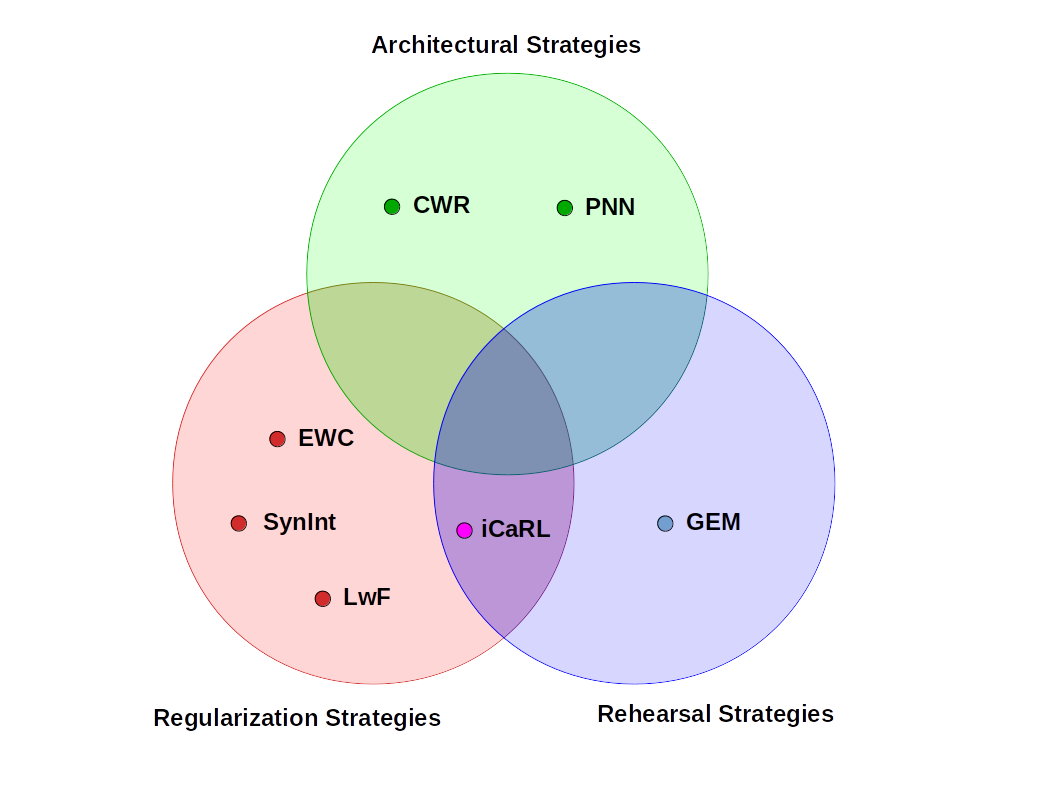
Fig. 1: Venn diagram of the most popular CL strategies, devided in Architectural, Regularization and Rehearsal strategies.
Summary Table
Here we provide a single table from which it is possible to get on which benchmark each strategy has been assessed and where (It would be unfair to report directly the accuracy results since the community has not agreed on a
"model invariant" evaluation metric yet):
| Strategy |
Perm. MNIST |
MNIST Split |
CIFAR Split |
ILSVRC2012 Split |
Atari Games |
CORe50 |
| CWR |
- |
- |
- |
- |
- |
[1] |
| PNN |
- |
- |
- |
- |
[8] |
- |
| EWC |
[5] |
- |
- |
- |
[5] |
[9] |
| SynInt |
[7] |
[7] |
[7] |
- |
- |
- |
| iCaRL |
- |
- |
[6] |
[6] |
- |
- |
| GEM |
[4] |
- |
[4] |
- |
- |
- |
| LwF |
- |
- |
- |
- |
- |
[9] |
If you want to learn more about the most common
CL Benchmarks check out our constantly updated page:
"Continuous Learning Benchmarks".
For more detailed accuracy results on
CORe50, you can instead take a look at our
living leaderboard!
References
| [1] |
Vincenzo Lomonaco and Davide Maltoni. "CORe50: a new Dataset and Benchmark for Continuous Object Recognition". Proceedings of the 1st Annual Conference on Robot Learning, PMLR 78:17-26, 2017. |
| [2] |
James Kirkpatrick & All. "Overcoming catastrophic forgetting in neural networks". Proceedings of the National Academy of Sciences, 2017, 201611835. |
| [3] |
Li Zhizhong and Derek Hoiem. "Learning without forgetting". European Conference on Computer Vision. Springer International Publishing, 2016. |
| [4] |
Lopez-Paz David and Marc'Aurelio Ranzato. "Gradient Episodic Memory for Continual Learning". European Conference on Computer Vision. Advances in Neural Information Processing Systems. 2017. |
| [5] |
Kirkpatrick James et al. "Overcoming catastrophic forgetting in neural networks." Proceedings of the National Academy of Sciences, 2017 |
| [6] |
Rebuffi Sylvestre-Alvise, Alexander Kolesnikov and Christoph H. Lampert. "iCaRL: Incremental classifier and representation learning." arXiv preprint arXiv:1611.07725, 2016. |
| [7] |
Zenke, Friedemann, Ben Poole, and Surya Ganguli. "Continual learning through synaptic intelligence". International Conference on Machine Learning. 2017. |
| [8] |
Rusu Andrei et al. "Progressive neural networks." arXiv preprint arXiv:1606.04671, 2016. |
| [9] |
Vincenzo Lomonaco and Davide Maltoni. CORe50 LeaderBoard. Website, 2017. |
| [10] |
Kemker Ronald et al. "Measuring Catastrophic Forgetting in Neural Networks." arXiv preprint arXiv:1708.02072 (2017). |

